
Collaborating on building family trees

Genealogy, an ancient practice, has seen people collaborating on family trees for centuries. Today, the predominant method for genealogical research involves the use of software, which facilitates collaboration.
I myself struggle with maintaining my genealogy data. As long as I’m the only one adding data, it’s easy. However, when it comes to ingesting data from others, I mostly rely on just manually copying information, which is often tedious and error-prone. Moreover, I don’t have a truly automated way of getting updates whenever a new piece of information appears in one of the sources I track.
In this discussion, explore how we can leverage technology for effective genealogical collaboration paying special attention to data privacy and ownership.
Today’s collaboration landscape
There are two distinct approaches to collaborating on a family tree. Firstly, individuals can work together on a unified database, where each person is represented by a single entry, allowing multiple users to update information about individuals and their relationships. Secondly, users may opt to maintain separate databases maintaining more control over the contents of the database.
The former method appears to be the most efficient. However, conflicts often arise — both regarding data accuracy, such as conflicting sources, and on a personal level among users. Preferences vary widely, some individuals prioritize meticulous detail, while others are more lenient regarding the quality of information they accept. Moreover, each person tends to focus on specific branches of the family tree relevant to them. Consequently, the reality of collaboration often leans towards the second approach, where individuals curate their own databases by copying information from various sources.
Different genealogy software varies in their approach to collaboration. When considering collaboration, one often thinks of online Web services such as WikiTree, geni.com, and MyHeritage which are explicitly designed for collaboration. However, there are drawbacks to these online platforms, particularly concerning data ownership and control over access. Not everyone is comfortable entrusting their valuable data to websites where they lack full control. Some individuals opt for self-hosted solutions like webtrees or TNG, offering complete control over data access but requiring more effort and typically incurring hosting expenses. Additionally, the collaboration tools in such self-hosted solutions may not be as robust as those in online services.
Alternatively, some prefer to keep their genealogy database offline, utilizing desktop applications like Gramps or Family Tree Maker (the latter being the most popular according to this poll). However, this approach complicates collaboration further, as desktop applications typically offer limited collaboration features. While some may allow for uploading data to Web services, this falls short of providing comprehensive collaboration functionality.
Furthermore, despite the existence of a standard for genealogy data exchange, GEDCOM, opting for a specific software to manage your data typically results in being tied to it. While most genealogy programs enable data export to GEDCOM, transferring data from one program to another often leads to loss of information. Although basic information is usually transferred accurately, some pieces of information may be stored differently across various programs (e.g. see information regarding exporting and importing GEDCOM data in Gramps). This challenge of data exchange further complicates collaboration when two individuals use different software to maintain their data.
My workflow
Here is my workflow for managing my genealogy data, a routine I’ve grown accustomed to and find challenging to alter now :-) I work on the family tree mostly myself and find the collaborative aspect of genealogy to be quite challenging.
I use GenealogyJ as the application to input data. It’s an old app that is not maintained anymore and I wouldn’t recommend it to anyone today. GenealogyJ doesn’t have it’s own data format, it stores the data directly as a GEDCOM file. I use git to store the file online and for version tracking. A similar sheme can also be achieved using Gramps and exporting the data to Gramps XML to store it in git (example), albeit requiring additional steps for importing and exporting the XML file.
For sharing my data, I rely on a series of scripts that generate several GEDCOM files with filtered data for different branches of the family. I then upload the files to the Web and share links to Topola Genealogy Viewer like this. If a cousin expresses interest in the raw data, I can direct them to the specific GEDCOM file containing data filtered to our shared part of the family tree. They can then utilize any tool of their preference to view the data or import it into any genealogy application for editing.
Regarding the ingestion of data from others, I predominantly resort to manual copying of information. Occasionally, I employ handwritten scripts to import data from external sources, although these solutions are typically one-off and do not scale well for different sources or other genealogists.
For instance, I use scripts to merge data from kielakowie.pl, a site maintained by a distant cousin of mine containing a large part of the family tree with my last name. Naturally, I’m only interested in the part of the data containing my relatives, which constitutes a small portion of the entire site.
Additionally, I enter my ancestors into WikiTree with the objective of enabling others to find me if they share common ancestors. Unfortunately, I lack automated tools to synchronize my local database with the data in WikiTree.
This is my workflow and there are likely dozens of different workflows people use. There is no standard and most widely used way of collaborating in this field. While online Web services do offer collaboration features, not everyone is willing to share their data in this manner, as mentioned earlier.
How I see collaborating with cousins
I would really like to make collaboration on the family tree easier. The primary use case I’m thinking of is collaborating with a cousin. When I work with a cousin on the family tree, we’re going to work together on the common part of our family trees. There will also be a part of my family tree that is not interesting for my cousin, for example my wife’s ancestors, and a part of their family tree that is not interesting for me. And by “not interesting” I also mean that I don’t want the other part shared for privacy reasons and also I don’t want individuals that are outside of my research scope to show up in my editor and my reports.
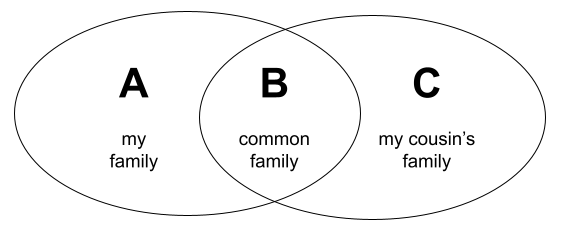
Of course, we can use one of the online Web services to place our data there. But I am cautious with placing my genealogy data in online services.
Technically, we could set up 3 git repositories for each of the three parts of the tree (A, B, C). We would then collaborate on B and have A and C for our private use. However, this approach fails pretty fast as it has a number of problems:
- I want to be able to see the whole tree in my genealogy application, not just one of the parts, e.g. to generate reports, visualizations etc.
- This approach doesn’t scale. What if there is another cousin that wants to join the genealogy fun? Then I have to do another split and the number of parts doesn’t grow linearly with the number of cousins.
Solutions I see
Given the impracticality of initially dividing the family tree into segments, I’ll be working on my entire family tree as a single database. I can still share specific parts of my data by filtering the dataset. If my cousin also shares the relevant part of his family tree with me, the challenge remains in automatically integrating this data into my own database. Automation is key as I aim to synchronize with my cousin as often as possible, ideally immediately upon any changes.
In the discussion below, I’ll assume all data is represented as GEDCOM files. Most genealogy software supports the GEDCOM standard. Although it may not be the best format for various reasons, and alternatives like GEDCOM X or Gramps XML exist, the actual data format does not really matter for this discussion and an actually implemented tool may use any other data format. This post intentionally does not aim to design any actual software but rather lay out the problem and a possible direction for solving it.
Let’s begin with a mostly manual process. Consider the following scenario:
- My cousin, Peter, makes a change in his database, perhaps by discovering the birth date of a common ancestor in an online birth record.
- Peter generates a filtered view of his database and shares the file with me.
- I review the changes since the last synchronization and manually incorporate the new information into my database.
Although I ultimately perform the copying manually, there are two parts of the process that should already be performed by software. Firstly, Peter must generate the filtered file, a task that could be handled either by a family tree application or an external program. For example, Gramps offers the ability to generate filtered data files. Secondly, to identify changes since the previous synchronization, I need to have retained the data from the previous synchronization and I need to use software capable of highlighting semantically meaningful data changes. In the worst case, I can compare line changes in a GEDCOM file.
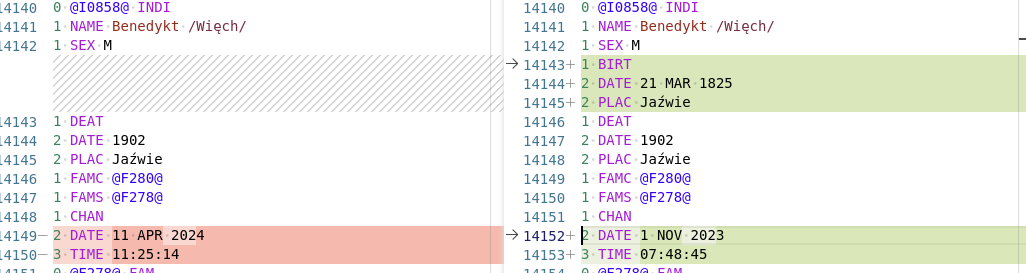
Now, there are a few missing pieces in this scenario:
- Once a change is displayed during synchronization, subsequent syncs won’t show it again because the “previous sync” file will now contain this information . This means I cannot perform another sync before incorporating all changes from the current sync.
- What if all the changes I received from Peter were ones he already received from me, rendering the updates unnecessary? It would be preferable to avoid manually determining what is new for me.
- What if this is the first time I’m performing the sync and I don’t have the previous synchronization data?
In essence, aside from comparing different versions of Peter’s data, I need to be able to find differences between my data and the data I received from Peter. This is a more challenging task for several reasons:
- The identifiers in both data files probably do not match.
- Both data files could be created by different pieces of software treating the GEDCOM standard a bit differently and with custom extensions.
To address the first issue, an initial step of matching individuals from both databases is necessary. Since I assume the synchronization process will occur regularly, not just once, the matches may be stored for subsequent syncs. To tackle representation differences, the diffing software may need a rich set of heuristics and custom rules for comparing data from different sources. Alternatively, a data format that provides unambiguous semantics could be used. However, given the inherent ambiguity in genealogy data, hand-coded heuristics may be unavoidable to reliably compare data.
Once we establish the functionality for matching and comparing two genealogy databases, we can define a richer scenario for importing data into our database.
- I receive a GEDCOM file with data from a cousin or from an internet source.
- Individuals in the incoming file are matched to individuals in my database. Matches are stored for future incremental imports. If this is a subsequent import, stored matches are used but new matches may still be discovered.
- Incoming data is filtered to a subset of data interesting for me (e.g. “only my blood relatives” or “only my ancestors”)
- Comparison software shows differences between my data and incoming data. If this is an incremental import, changes that have already been processed in previous imports are hidden.
- Looking at the incoming changes, I can copy the incoming data into my database or ignore a change. The action taken for the specific piece of information is stored so that subsequent imports can ignore changes that were already processed.
Note that copying incoming changes is more nuanced than it may seem. Sometimes, I’ll want to replace my information with incoming information, e.g. fixing a bad birth date. Other times, I’ll want to add an additional piece of information, like an alternative name the person was known as. In some situations, incoming information needs to be merged with my data, for instance updating a textual biography.
The described scenario should work for both close collaborators with whom I exchange information often and distant cousins that just share their data and aren’t necessarily interested in accepting contributions from me. Moreover, the same flow should work for ingesting data from Web services like WikiTree or MyHeritage, assuming you can programatically take out the data.
There is also the question of automation. Should I review all changes manually or should I allow automatic copying of some, most or all information? I guess this is something one should make a concious decision about. I’ll trust some sources more than others. I’ll trust my cousin makes good changes about his side of the family but I’ll want to review more carefully changes to our common ancestors.
In practice, the sync tool could work a bit like the “automatic matches” feature in one of the online Web services. You would get a message similar to “hey, we found a match for one of the individuals in your database with this information that you don’t have yet.”
When actual software will be designed, there will be the question of where to store the matches, change history, etc. This information will most likely be stored in a place that is separate from the genealogy data itself. However, it may be useful to actually store some information together with the actual data, e.g. identifiers in other databases, sources of information, maybe even rejected information together with a note saying why it was rejected.
Existing merge software
Several applications offer family tree merge functionality. Below is a compilation of the ones I’ve come across. If you’re aware of any other software that provides similar features, I’d appreciate your input.
Gramps Import Merge Tool
https://gramps-project.org/wiki/index.php/Addon:Import_Merge_Tool
This tool shows differences between two Gramps databases. However, it only works when the 2 family trees are derived from the same Gramps database. The assumption is that matching individuals already have identical identifiers, so the matching part of the process is not needed.
genmatcher
http://www.mudcreeksoftware.com/
This program does a lot of what I described. However, I have only tried the demo version which is very limited.
GenMerge
http://genmerge.com/
The site description promises a lot of what I described. There is a trial version but VirusTotal says there’s a trojan in the exe file, so I didn’t try it. The site offers to buy a licence for the app.
gedcom CLI tool
https://github.com/elliotchance/gedcom
This is an open source command line tool that does provide a comparison functionality.
Other ideas
Here are several ideas that may be worth researching. While I haven’t looked too deep into integrating them with genealogy software, they’re definitely on my radar. Each of the ideas in one way on another centers around data ownership and control, which aligns closely with my emphasis on the importance of these factors in genealogy software.
local-first software
The local-first software movement focuses on building software that works offline and provides full control over data ownership together with collaboration functionality. Sounds like exactly what I want for genealogy software. Much of the development centers around conflict-free replicated data types and a model of storing all data locally and using the network to synchronize data between computers. Although the ideas sound like a perfect fit for genealogy software, there are no ready solutions that can be simply adopted for family tree collaboration.
I have developed the Topola Genealogy Viewer that provides some of the local-first features. Being a progressive web app, it has the capability of working offline and works with local data. However, it does not match all the local-first principles as it is a read-only application for vizualizing family trees and does not feature collaboration.
Solid Project
The Solid Project focuses on a decentralized method of securely storing data. Data stored in a Pod is owned and controlled by its owner and the owner controls who can access the data. The concept of storing data with fine-grained access control is appealing for genealogy data. It’s an open question about how exactly genealogy data can be stored this way.
Mastodon inspiration
Although a totally different use case, Mastodon takes an interesting approach of reimplementing a centralized system in a decentralized federated fashion. Imagine a federated genealogy system where anyone can spin up their own family tree website that is automatically connected to other such websites. For instance, your own family tree could show “see siblings of John in a family tree managed by Mary, hosted at somewhere-else.org”. Similarly to Mastodon, both large community-managed servers and small self-hosted servers could exist side by side.
What’s next
Next, I’d like to dig deeper into the technical aspects of realizing these ideas. One possibility is to explore methods for incorporating the described workflows into existing software. My first choice would be Gramps since it’s open source and actively developed. Alternatively, I could consider developing a standalone software solution capable of working with GEDCOM or Gramps XML files and providing merge functionality. Further research is necessary to determine the most viable approach for actual implementation.